Datasets - Metrics
Artefact counting metrics
Artefact counting metrics are FILE, FUNC and CLAS.
- The number of files ( FILE ) counts the number of source files in the project, i.e. which have an extension corresponding to the defined language (.java for Java or .c and .h files for C).
- The number of functions ( FUNC ) sums up the number of methods or functions recursively defined in the artefact.
- The number of classes ( CLAS ) sums up the number of classes defined in the artefact and its sub-defined artefacts. One file may include several classes, and in Java anonymous classes may be included in functions.
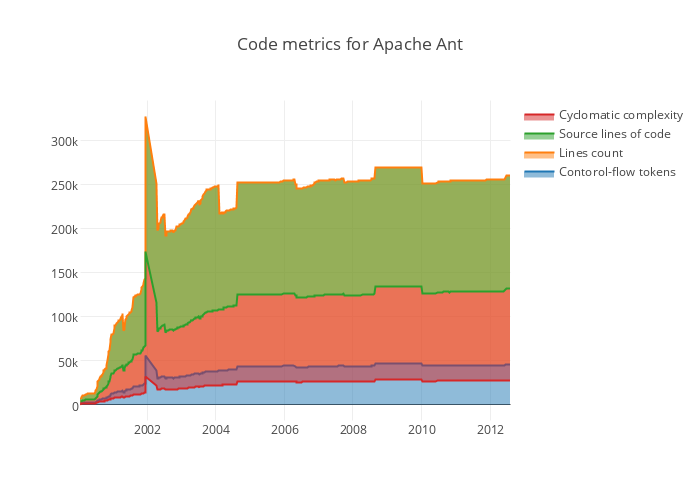
Line counting metrics
Line counting metrics are often used to grasp the size of code from different perspectives. We propose the following counting metrics: STAT, SLOC, ELOC, CLOC, MLOC and BRAC.
- The number of statements ( STAT ) counts the total number of instructions. Examples of instructions include control-flow tokens, plus else, cases, and assignments.
- Source lines of code ( SLOC ) is the number of non-blank and non-comment lines in code.
- Effective lines of code ( ELOC ) also removes the number of lines that contain only braces.
- Comment lines of code ( CLOC ) counts the number of lines that include a comment in the artefact. If a line includes both code and comment, it will be counted in SLOC, CLOC and MLOC metrics.
- Mixed lines of code ( MLOC ) counts the number of lines that have both code and comments
- Braces ( BRAC ) counts the number of lines that contain only braces.
The relationships among these metrics are the following:
SLOC = ELOC + BRAC
LC = SLOC + BLAN + CLOC - MLOC
LC = (ELOC + BRAC) + BLAN + CLOC - MLOC
COMR = ((CLOC + MLOC) × 100)/(ELOC + CLOC))
Control flow complexity metrics
- The maximum nesting level ( NEST ) counts the highest number of imbricated code (including conditions and loops) in a function. Deeper nesting threatens understandability of code and induces more test cases to run the different branches. Practitioners usually consider that a function with three or more nested levels becomes significantly more difficult for the human mind to apprehend how it works.
- The number of execution paths ( NPAT ) is an estimate of the possible execution paths in a function. Higher values induce more test cases to test all possible ways the function can execute depending on its parameters. An infinite number of execution paths typically indicates that some combination of parameters may cause an infinite loop during execution.
- The cyclomatic number ( VG ), a measure borrowed from graph theory and introduced by McCabe in [130] is the number of linearly independent paths that comprise the program. To have good testability and maintainability, McCabe recommends that no program modules (or functions as for Java) should exceed a cyclomatic number of 10. It is primarily defined at the function level and is summed up for higher levels of artefacts.
- The number of control-flow tokens ( CFT ) counts the number of control-flow oriented operators (e.g. if, while, for, switch, throw, return, ternary operators, blocks of execution). else and case are typically considered a part of respectively if and switch and are not counted.
Halstead metrics
Halstead proposed in his Elements of Software Science [82] a set of metrics to estimate some important characteristics of a software. He starts by defining 4 base measures:
- the number of distinct operands ( DOPD , or n2),
- the number of distinct operators ( DOPT , or n1 ),
- the total number of operands ( TOPD , or N2 ),
- the total number of operators ( TOPT , or N1 ).
Together they constitute the following higher-level derived metrics:
- program vocabulary: n = n1 + n2
- program length: N = N1 + N2
- program difficulty: D = (n1 / 2) x (N2 / n2)
- program volume: V = N log2 n,
- estimated effort needed for program comprehension: E = D × V.
In the data sets, only the four base measures are retrieved: dopd, dopt, topd, and topt. Derived measures are not provided in the data sets since they can all be computed from the provided base measures.
Rules-oriented measures
- NCC is the number of non-conformities detected on an artefact. From the practices perspective, it sums the number of times any rule has been transgressed on the artefact (application, file or function).
- The rate of acquired practices ( ROKR ) is the number of respected rules (i.e. with no violation detected on the artefact) divided by the total number of rules defined for the run. It shows the number of acquired practices with regards to the full rule set.
Object-oriented measures
Three measures are only available for object-oriented code. They are the number of classes (CLAS), the maximum depth of inheritance tree (DITM), and the above-mentionned rate of acquired rules (ROKR).
- The number of classes ( CLAS ) sums up the number of classes defined in the artefact and its sub-defined artefacts. One file may include several classes, and in Java anonymous classes may be included in functions.
- The maximum depth of inheritance tree ( DITM ) of a class within the inheritance hierarchy is defined as the maximum length from the considered class to the root of the class hierarchy tree and is measured by the number of ancestor classes. In cases involving multiple inheritance, the DITM is the maximum length from the node to the root of the tree [161]. It is available solely at the application level. A deep inheritance tree makes the understanding of the object-oriented architecture difficult. Well structured OO systems have a forest of classes rather than one large inheritance lattice. The deeper the class is within the hierarchy, the greater the number of methods it is likely to inherit, making it more complex to predict its behavior and, therefore, more fault-prone [77]. However, the deeper a particular tree is in a class, the greater potential reuse of inherited methods [161].
- ROKR is another measure specific to object-oriented code, since it is computed relatively to the full number of rules, including Java-related checks. In the case of C projects only the SQuORE rules are checked, so it loses its meaning and is not generated.
Configuration management metrics
Configuration management systems hold a number of meta-information about the modifications committed to the project repository. The following metrics are defined:
- The number of commits ( SCM_COMMITS ) counts the commits registered by the software configuration management tool for the artefact on the repository (either the trunk or a branch). At the application level commits can concern any type of artefacts (e.g. code, documentation, or web site). Commits can be executed for many different purposes: e.g. add feature, fix bug, add comments, refactor, or even simply re-indent code.
- The number of fixes ( SCM_FIXES ) counts the number of fix-related commits, i.e. commits that include either the fix, issue, problem or error keywords in their message. At the application level, all commits with these keywords in message are considered until the date of analysis. At the file level, it represents the number of fix-related revisions associated to the file. If a file is created while fixing code (i.e. its first version is associated to a fix commit) the fix isn’t counted since the file cannot be considered responsible for a problem that has been detected when it wasn’t there.
- The number of distinct committers ( SCM_COMMITTERS ) is the total number of different committers registered by the software configuration management tool on the artefact. On the one hand, having less committers enforces cohesion, makes keeping coding and naming conventions respected easier, and allows easy communication and quick connection between developers. On the other hand, having a large number of committers means the project is active; it attracts more talented developers and more eyes to look at problems. The project has also better chances to be maintained over the years.
It should be noted that some practices may threaten the validity of this metric. As an example occasional contributors may send their patches to official maintainers who review it before integrating it in the repository. In such cases, the commit is executed by the official committer, although the code has been originally modified by an anonymous (at least for us) developer. Some core maintainers use a convention stating the name or identifier of the contributor, but there is no established or enforced usage of such conventions. Another point is that multiple online personas can cause individuals to be represented as multiple people [86]. - The number of files committed ( SCM_COMMIT_FILES ) is the number of files associated to commits registered by the software configuration management tool. This measure allows to identify big commits, which usually imply big changes in the code.
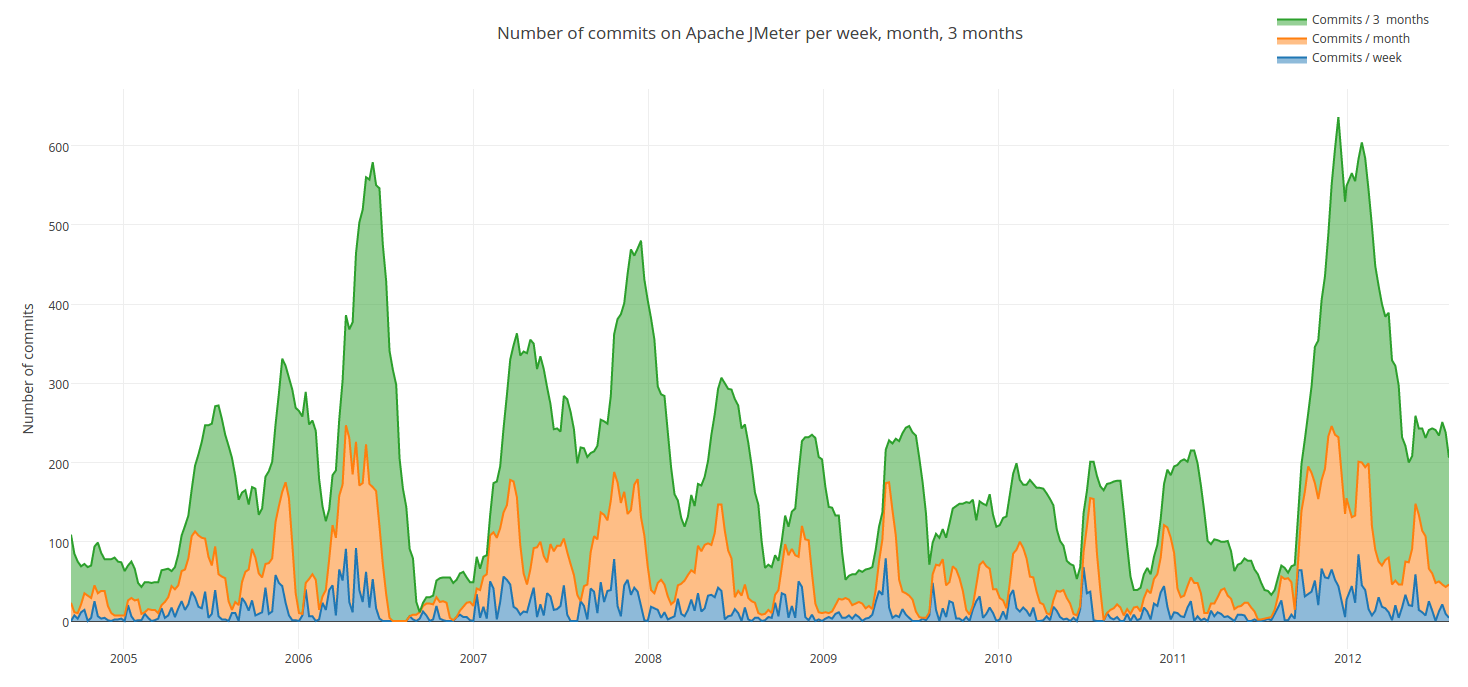
To reflect recent activity on the repository, we retrieved measures both on a limited time basis and on a global basis: in the last week (e.g. SCM_COMMITS_1W ), in the last month (e.g. SCM_COMMITS_1M ), and in the last three months (e.g. SCM_COMMITS_3M ), and in total (e.g. SCM_COMMITS_TOTAL ).
Communication metrics
Communication metrics show an unusual part of the project: people’s activity and interactions during the elaboration of the product. Most software projects have two communication media: one targeted at the internal development of the product, for developers who actively contribute to the project by committing in the source repository, testing the product, or finding bugs (a.k.a. developers mailing list); and one targeted at end-users for general help and good use of the product (a.k.a. user mailing list).
The type of media varies across the different forges or projects: most of the time mailing lists are used, with a web interface like MHonArc or mod_mbox. In some cases, projects may use as well forums (especially for user-oriented communication) or NNTP news servers, as for the Eclipse foundation projects. The variety of media and tools makes it difficult to be extensive; however data providers can be written to map these to the common mbox format. We wrote connectors for mboxes, MHonArc, GMane and FUDForum (used by Eclipse). The following metrics are defined:
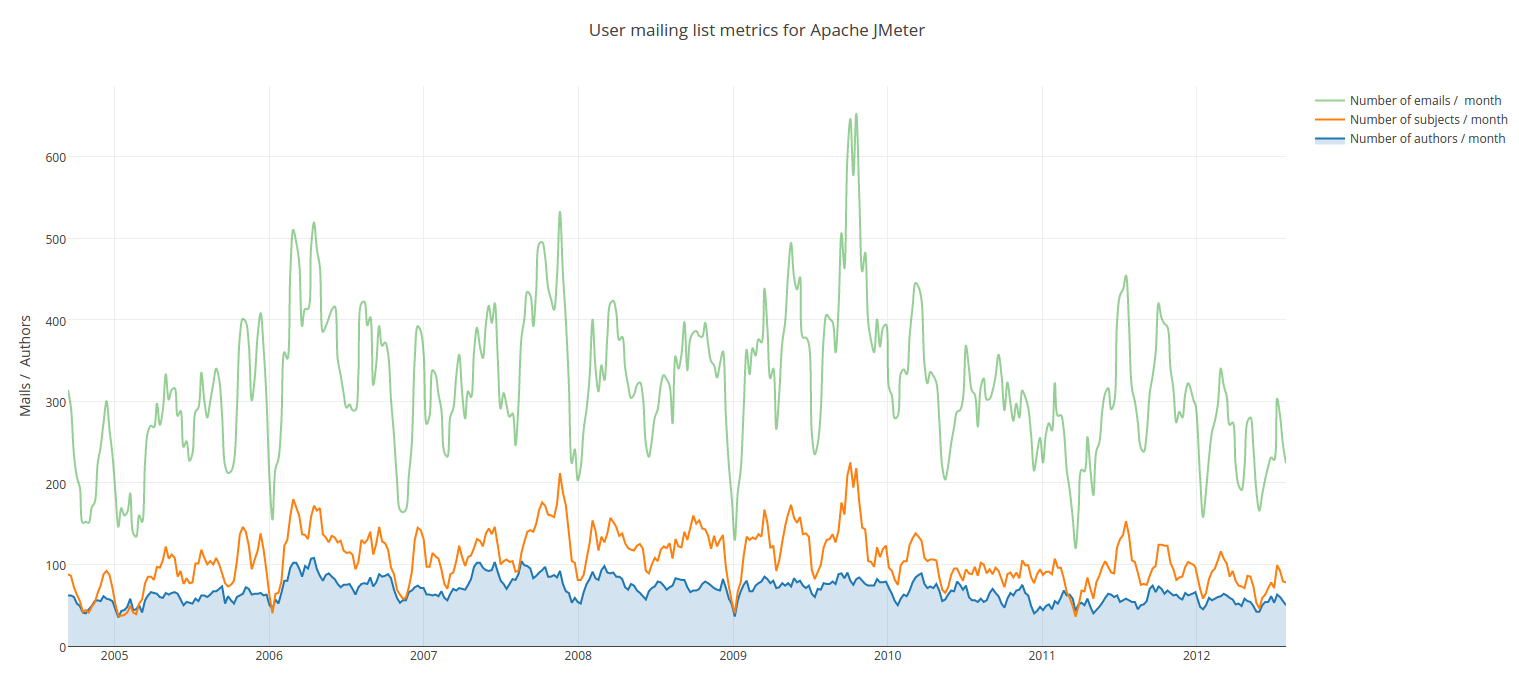
- The number of posts ( COM_DEV_VOL , COM_USR_VOL ) is the total number of mails posted on the mailing list during the considered period of time. All posts are counted, regardless of their depth (i.e. new posts or answers).
- The number of distinct authors ( COM_DEV_AUTH , COM_USR_AUTH ) is the number of people having posted at least once on the mailing list during the considered period of time. Authors are counted once even if they posted multiple times, based on their email address.
- The number of threads ( COM_DEV_SUBJ , COM_USR_SUBJ ) is the number of diffent subjects (i.e. a question and its responses) that have been posted on the mailing list during the considered period of time. Subjects that are replies to other subjects are not counted, even if the subject text is different.
- The number of answers ( COM_DEV_RESP_VOL , COM_USR_RESP_VOL ) is the total number of replies to requests on the user mailing list during the considered period of time. A message is considered as an answer if it is using the Reply-to header field. The number of answers is often associated to the number of threads to compute the useful response ratio metric.
- The median time to first reply ( COM_DEV_RESP_TIME_MED , COM_USR_RESP_TIME_MED ) is the number of seconds between a question (first post of a thread) and the first response (second post of a thread) on the mailing list during the considered period of time.